
1. Vision-Language Understanding: I am interested in pursuing research on enhancing Vision-Language Models (VLMs) through Representation Learning and Transfer Learning, with a focus on Compositionality, Alignment, and Grounding to better integrate visual and textual data.
2. Responsible VLMs: I aim to explore ways to address biases and hallucinations in VLMs by establishing benchmarks for fairer and more ethical systems, contributing to the development of inclusive and trustworthy Social AI.
3. Datasets and Synthetic Data: I am keen on investigating the role of datasets in building VLMs, particularly the potential of synthetic data generation to overcome limitations and enable diverse, scalable, and high-quality training resources.
Check out my ongoing projects in the section below.Current Research Projects
-
IH Risk Model:
(I could not upload the source code due to confidentiality agreements but happy to walk through)
In collaboration with Penn Medicine, I am working on developing a model to predict the risk of Incisional Hernia (IH) in patients post-surgery by using real-world operative notes and intraoperative EHR data.- 🔄 Reduced model tuning time by 10× by developing an AutoML pipeline using FLAML for risk prediction (recall = 0.90), enabling faster iteration over logistic and tree-based models.
- Engineered few-shot GPT-4 pipelines to extract surgical features (e.g., incision type, ostomy, closure) from 10K+ operative notes, reducing noisy extractions by 30% vs. RoBERTa-based baselines.
- Modularized LLM backend to support OpenAI and Mistral; implemented parallelized batch inference and memory-efficient chunking to support large-scale processing.
-
📊 Visualized latent structure across surgical feature types using OpenAI text embeddings, PCA, and Seaborn. Applied
JSON schema validation using
jsonschemato ensure extraction integrity. - Spun up a FastAPI server + TypeScript frontend for RAG workflow, slashing surgical data analysis time from hours to seconds through ChromaDB vector embeddings and GPT-4 integration.
-
Misinformation:
- Research Goal: Working on identifying misinformation on social media (FB posts, YouTube interactions) and whether or not it relates to health outcomes for people categorized on the basis of race (white/black) & urbanity (rural/urban).
- Developed a URL based misinformation-detection model that detected around 1k misinformed posts out of 1mm FB posts.
- Implemented semantic similarity and entailment analysis using a pre-trained RoBERTa model to detect misinformation based on post alignment with trusted claims.
- Extracted linguistic features from posts using DLATK and applied LDA for topic modeling- computed Pearson’s Correlation for these topic distributions with depression scores computed from user surveys to identify key linguistic markers.
- Implemented sentiment analysis using a pre-trained ‘DistilBERT’ Transformer model to evaluate user emotions from social media posts, leading to insights on engagement patterns segmented by race and urbanity.
- Unified data from various online survey platforms in a secured server via MySQL and performed feature engineering in Pandas to prepare data for further downstream tasks.
-
"Agency" determination using NLP:
In collaboration with the Department of Psychology at Penn, I aim to analyze the evolution of male and female "Agency" in historical texts using AI and NLP. Our multi-source dataset—magazines, movie scripts, and NYT bestsellers—is processed with OCR and SpaCy to extract linguistic structures. Leveraging GPT, we aim label agents (action-takers) and patients (acted-upon entities), revealing gendered patterns over time. This data-driven approach uncovers shifts in societal narratives, offering deep insights into cultural and historical trends.
Publication: pre-prints
(* denotes equal contribution)-
Enhancing Retrieval in QA Systems with Derived Feature Association
Keyush Shah, Abhishek Goyal*, Isaac Wasserman*
arXiv preprint, 2024
paper | arxiv | code
Portfolio of Selected Projects
Machine Learning Systems/MLOps
Deep Learning
-
Computer Vision
-
MultiModal
-
Computational Linguistics/NLP
Computer Systems & Data Engineering
Probability & Statistical Modeling
Project Descriptions
-
Particle Agent

Backend Architecture & Technologies
- Built a context-aware conversational agent for product and order support using FastAPI, LangChain, and Pinecone, enabling multi-turn chat for PartSelect customers.
- Engineered Retrieval-Augmented Generation (RAG) for product queries, leveraging OpenAI embeddings and Pinecone vector search for >97% relevant retrieval accuracy and <200ms response latency.
- Designed tool-based logic for transaction/order support, with LLM fallback for complex queries, improving answer accuracy by 40% and reducing manual intervention.
Session Memory & Entity Resolution
- Implemented session-based memory using ConversationBufferMemory and custom entity tracking, enabling >95% accurate follow-up handling and robust multi-turn interactions.
- Developed entity extraction and context reuse logic, reducing user friction and repeated clarification requests by 35%.
Data Ingestion & Privacy
- Automated ingestion of synthetic product and transaction data into Pinecone, scaling to 1,000+ products and 5,000+ transactions, ensuring privacy compliance and rapid deployment.
- Achieved 100% data coverage for all supported product and transaction queries.
Frontend Development
- Developed a real-time chat frontend using React, Vite, and TypeScript, integrating Axios for backend communication and session management.
- Enhanced support workflow efficiency by 40% and improved user satisfaction scores through responsive UI and seamless multi-turn chat experience.
-
Ride Duration Prediction

🧱Model Development
- Processed NYC taxi trip data with engineered features like pickup/dropoff zones and trip distance.
- Tuned XGBoost and Random Forest models using Hyperopt, improving RMSE by ~30%.
- Tracked all experiments, metrics, and artifacts using MLflow.
🧱 Pipeline Orchestration
- Designed a modular ML pipeline using Apache Airflow to automate preprocessing and training stages.
- Configured Docker + CeleryExecutor for reproducible, distributed task execution.
- Used XCom for smooth data passing and monitoring through the DAG.
🧱 Experiment Management
- Logged models to MLflow Model Registry, versioned them, and promoted top models to "Production" stage.
- Enabled consistent experiment comparison and artifact retrieval.
🧱 Deployment
- Deployed the trained model as a REST API using Flask, allowing real-time predictions via user input.
- Containerized the app with Docker to simulate a real-world, always-on service.
-
Image Reconstruction using Diffusion Transformers

I developed a PatchVAE model to encode facial features from the CelebA dataset, followed by training a Diffusion model using the VAE's latent representations. This approach successfully reconstructed and generated realistic human face images. The model achieved an impressive FID score of 14.2, highlighting its effectiveness in producing high-quality outputs.
| code | Reference Paper -
Instance Segmentation: By location

I implemented an advanced instance segmentation framework inspired by the SOLO (Segmenting Objects by Locations) model. It features a ResNet backbone for robust feature extraction and a Feature Pyramid Network (FPN) to handle multi-scale object representations efficiently. The architecture consists of two main branches. The Category Prediction Branch assigns pixels to grid-based instance categories, leveraging spatial information to effectively localize and distinguish objects of varying sizes.Meanwhile, the Mask Segmentation Branch generates accurate binary masks using a spatially sensitive, fully convolutional network, eliminating the need for traditional bounding boxes or complex post-processing. This end-to-end trainable system simplifies the segmentation pipeline, learning directly from mask annotations to enhance efficiency and deliver high performance across diverse object segmentation tasks.
| code | Reference Paper -
Improving Depth Estimation of DinoV2

The research demonstrated that combining temporal information across frames reduces per-frame errors, enhancing the scaling accuracy of depth maps. The project explored methods to improve depth estimation in DINOv2 using iterative strategies. Initially, ORB features and phase correlation were applied to align depth maps of consecutive frames explicitly. This approach leveraged the spatial shifts between frames to average depth maps and achieved modest reductions in MSE with minimal latency. However, limitations in alignment accuracy due to perspective distortions motivated further refinement.
Subsequently, a CNN-based adapter was integrated between the DINOv2 encoder and depth adapter. This adapter utilized phase-correlation-derived pixel shifts as additional input to adjust and combine DINO features from consecutive frames. The CNN introduced an inductive bias for local feature alignment, leading to a significant 23.8% reduction in MSE, outperforming vanilla DINOv2-base while being faster. Regularization techniques were later introduced to preserve high-resolution details in depth maps, improving output quality while maintaining accuracy.
| code | Reference Paper -
FitBit

Designed and developed a Django-based AI chatbot for health-related conversations, integrating PostgreSQL for robust patient data management and Langchain for LLM-agnostic model orchestration. Implemented dynamic entity extraction to capture key details like medications and appointment preferences, optimized memory usage for long conversations, and enabled automated escalation of appointment and treatment requests.
| Github code -
Multithreaded Image Blurring with POSIX Threads
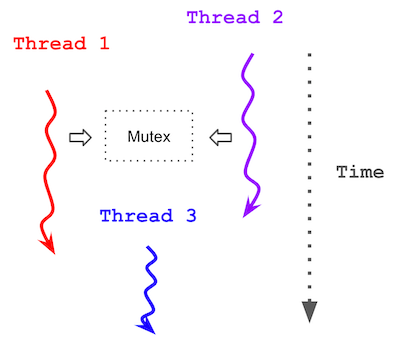
- Developed a multithreaded image processing pipeline to apply a box blur on bitmap (BMP) images using POSIX threads in C++.
- Achieved a 2.8x speedup compared to the sequential baseline (from 3251 ms to 1165 ms) on a quad-core CPU, using 4 threads on a moderately large input image and a blur radius of 8.
- Implemented dynamic workload partitioning by dividing the image into non-overlapping horizontal slices, assigned evenly across threads to eliminate write conflicts and maintain cache locality.
- Managed per-thread argument structures using dynamically allocated memory.
- Designed the system to operate entirely in shared memory without mutexes by restricting writes to thread-local output regions, enabling lock-free parallelism.
- Optimized memory access by ensuring threads performed read-only access on the input image and wrote exclusively to disjoint rows in the output buffer (
BitMap), avoiding contention and ensuring correctness.
-
Scalable ETL Pipelines with Microsoft Azure

In this project, I implemented a robust ETL (Extract, Transform, Load) pipeline using Azure cloud services to process and analyze data efficiently. The pipeline began with data ingestion from HTTP sources and SQL databases. Using Azure Data Factory (ADF), I created linked services to connect to these data sources and developed data pipelines to automate the extraction of raw data. The ingested data was stored in Azure Data Lake Storage Gen2 (ADLS Gen2) as the raw data layer.
For data transformation, I utilized Azure Databricks, where the raw data was processed through data cleansing, aggregation, and feature engineering to prepare it for downstream analysis. The transformed data was then stored back in ADLS Gen2 in a structured format. Finally, the processed data was imported into Azure Synapse Analytics, where it was further analyzed. This comprehensive ETL pipeline enabled seamless data movement and transformation, leveraging Azure's ecosystem for efficient data processing and analysis.
| Github code -
Analyzing Consumer Behavior in Mobile Plan Selection Using Statistical Modeling

AIM
The objective of this project is to analyze the distribution of the number of lines included in a customer's primary mobile phone plan. By leveraging statistical modeling, particularly Negative Binomial Distribution (NBD) variations, we aim to understand consumer behavior in selecting family or individual mobile plans. The analysis also seeks to determine underlying patterns in purchasing decisions, quantify market potential, and explore the heterogeneity within the dataset.
METHOD
To analyze the dataset, we employed statistical modeling techniques focusing on count data. The primary methodology involved fitting different versions of the Negative Binomial Distribution (NBD) to account for observed trends:
- Shifted NBD Model – Used to model the distribution, accounting for the absence of zero values in the dataset.
- Shifted NBD with a Spike at 1 – Introduced to capture the segment of customers who strongly prefer single-line plans.
- Truncated NBD Model – Implemented to estimate the proportion of potential customers who might have opted for zero lines but were excluded from the dataset.
- Gamma Distribution Analysis – Applied to measure the propensity of customers to purchase more than four lines.
Various model evaluation techniques, including Q-Q plots, chi-square likelihood ratio tests, and p-value assessments, were used to determine the fit and effectiveness of the models.
Conclusion
Conclusion The analysis confirmed that most customers opt for one to four lines per mobile plan, with a significant number of users preferring single-line plans due to convenience. The presence of a right-censored dataset and high homogeneity suggested that purchasing additional lines is influenced by external factors, such as social contagion, promotions, or family needs.
| Project Link -
Deepfake Detection

Deepfake detection research focuses on identifying and analyzing manipulated video content generated using advanced generative models. By curating extensive video datasets and developing innovative annotation frameworks, researchers aim to refine the detection of both visual and temporal artifacts. State-of-the-art Video Vision-Language Models (VLMs) such as VideoLaMA, BLIP, and LLaVA are evaluated by integrating synthetic data and annotated explanations to enhance the categorization of artifacts and improve detection accuracy. Additionally, methodologies like Kendall Tau’s correlation and reliability analysis are employed to verify data and align annotations. These techniques help assess inter-annotator agreement on deformation labels, providing robust benchmarks for evaluating the performance of current state-of-the-art detection models.
| Github code -
Traversability Estimation

Developed a terrain classification model using Semantic Segmentation and an attention enhanced Fully Convolutional Network, achieving a 2% improvement in IoU. Enhanced off-road navigation for autonomous vehicles by optimizing path planning and terrain adaptability.
paper | code -
Bangalore House Prediction
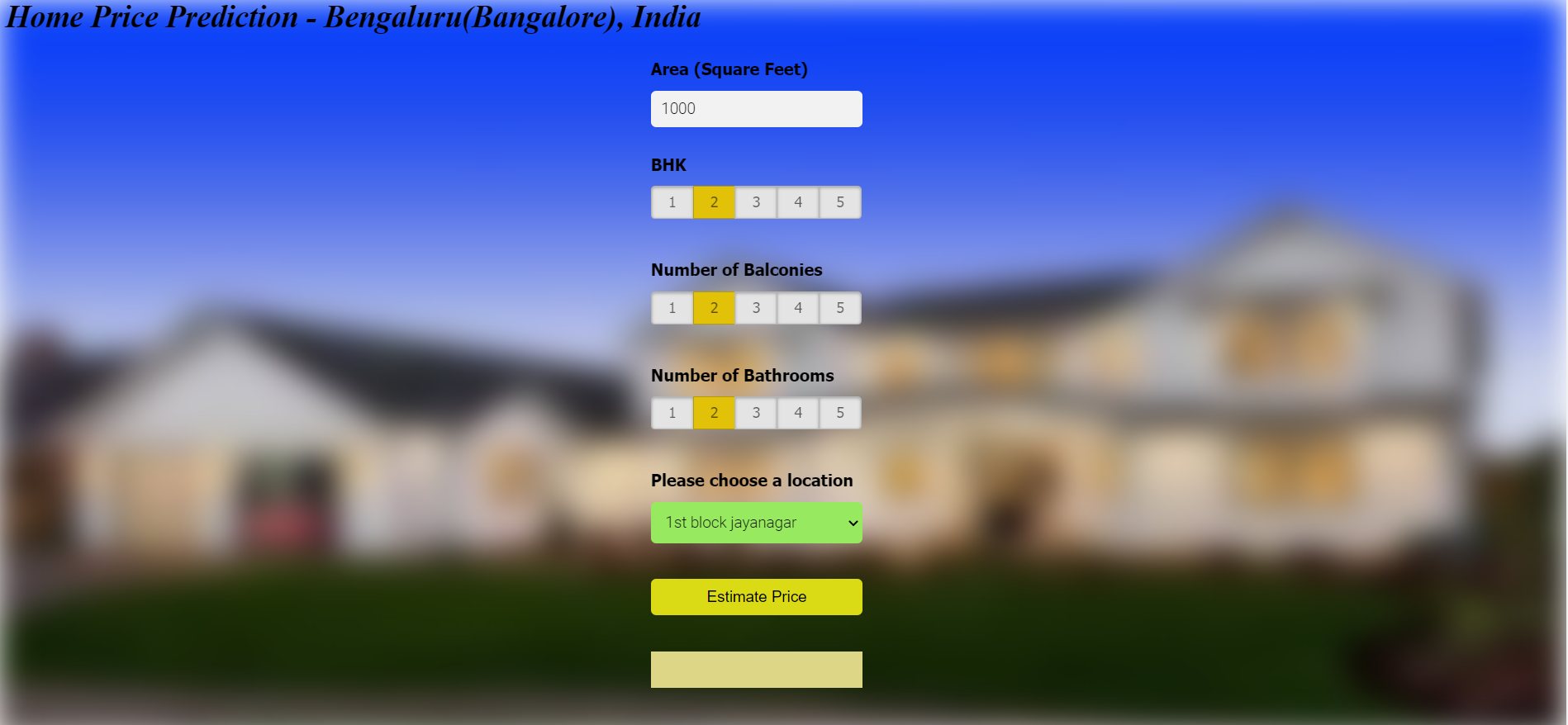
In this project, a machine learning model was developed to predict house prices in Bangalore using the sklearn library. The dataset was sourced from Kaggle and preprocessed using NumPy and Pandas for data cleaning, including outlier detection, feature engineering, and dimensionality reduction. The model was built using linear regression, with hyperparameter tuning implemented through GridSearchCV and performance evaluated using k-fold cross-validation.The application was powered by a Flask server, which acted as the backend to handle HTTP requests. The Flask server loaded the saved machine learning model and processed user inputs like square footage and number of bedrooms to return predicted prices. A front-end interface was built using HTML, CSS, and JavaScript, allowing users to input property details and retrieve price predictions dynamically via calls to the Flask API. The entire workflow integrated Python-based tools and libraries, offering a robust and user-friendly application for real estate price prediction.
| code -
Topic-Modelling-with-Latent-Dirichlet-Allocation

This project focuses on implementing Latent Dirichlet Allocation (LDA) for topic modeling, a natural language processing technique that classifies text into topics based on the corpus's underlying word distributions. Using libraries like NLTK, Gensim, and SpaCy, text preprocessing involved cleaning data with RegEx and preparing it for analysis. Key steps included generating word clouds to visualize word frequency distributions, computing coherence and perplexity scores to optimize the number of topics, and identifying the dominant topic for each document along with its percentage contribution. The LDA model revealed the proportion of documents belonging to the top six dominant topics, facilitating deeper insights into the dataset's structure. Interactive visualizations further enhanced the interpretability of the results, making the analysis accessible and insightful. This project demonstrated a robust approach to uncovering hidden thematic patterns in text data.
| code