
1. Vision-Language Understanding: I am interested in pursuing research on enhancing Vision-Language Models (VLMs) through Representation Learning and Transfer Learning, with a focus on Compositionality, Alignment, and Grounding to better integrate visual and textual data.
2. Responsible VLMs: I aim to explore ways to address biases and hallucinations in VLMs by establishing benchmarks for fairer and more ethical systems, contributing to the development of inclusive and trustworthy Social AI.
3. Datasets and Synthetic Data: I am keen on investigating the role of datasets in building VLMs, particularly the potential of synthetic data generation to overcome limitations and enable diverse, scalable, and high-quality training resources.
Check out my ongoing projects in the section below.Current Research Projects
Publication: Pre-prints
Project Descriptions
Surgical Note Extraction System
LLM Chains · FastAPI · TypeScript · GPT-4 · Clinical NLP- Built an end-to-end system that extracts structured surgical data from unstructured operative notes using a 10-step sequential LLM chain, replacing manual clinician review.
- Designed a posthoc rule engine with 20+ clinical validation rules enforcing mutual exclusivity, edge-case handling, and fallback logic for surgical concepts.
- Implemented an LLM-as-judge evaluation layer that reviews each extraction step, flags low-confidence outputs, and surfaces reasoning logs for human-in-the-loop review.
Particle Agent
FastAPI · LangChain · Pinecone · React · TypeScript- Engineered RAG for product queries with OpenAI embeddings and Pinecone vector search for >97% retrieval accuracy and <200ms response latency.
- Implemented session-based memory with >95% accurate follow-up handling and robust multi-turn interactions.
- Developed a real-time chat frontend using React, Vite, and TypeScript.

Ride Duration Prediction
XGBoost · Hyperopt · MLflow · Airflow · Docker · Flask- Tuned XGBoost and Random Forest models using Hyperopt, improving RMSE by ~30%.
- Designed a modular ML pipeline using Apache Airflow with Docker + CeleryExecutor.
- Deployed the trained model as a REST API using Flask, containerized with Docker.

Image Reconstruction using Diffusion Transformers
PatchVAE · Diffusion Transformer · CelebA- Developed a PatchVAE model to encode facial features from the CelebA dataset, trained a Diffusion model on VAE latent representations.
- Achieved an FID score of 14.2, producing high-quality realistic face images.

Instance Segmentation: By Location
ResNet · FPN · SOLO · PyTorch- Implemented an instance segmentation framework inspired by SOLO with ResNet backbone and Feature Pyramid Network.
- End-to-end trainable system eliminating the need for bounding boxes or complex post-processing.

Improving Depth Estimation of DINOv2
DINOv2 · CNN Adapter · Phase Correlation · ORB- Integrated a CNN-based adapter achieving a 23.8% reduction in MSE, outperforming vanilla DINOv2-base while being faster.
- Combined temporal information across frames to reduce per-frame errors and enhance depth map accuracy.

FitBit ChatBot
Django · PostgreSQL · LangChain- Designed a Django-based AI chatbot for health-related conversations with PostgreSQL for patient data management.
- Implemented dynamic entity extraction for medications and appointment preferences with automated escalation.

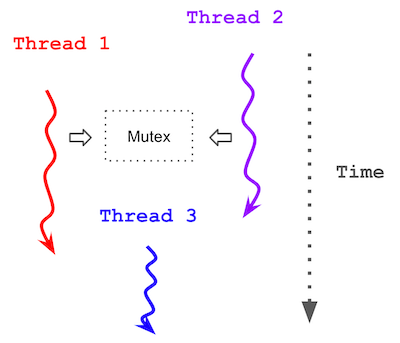
Multithreaded Image Blurring with POSIX Threads
C++ · POSIX Threads · Shared Memory- Achieved a 2.8x speedup compared to the sequential baseline (from 3251 ms to 1165 ms) using 4 threads.
- Designed lock-free parallelism via shared memory without mutexes, restricting writes to thread-local output regions.
Scalable ETL Pipelines with Microsoft Azure
Azure Data Factory · Databricks · ADLS Gen2 · Synapse- Implemented a robust ETL pipeline using Azure Data Factory for automated data ingestion from HTTP and SQL sources.
- Transformed data via Azure Databricks and loaded into Synapse Analytics for downstream analysis.

Analyzing Consumer Behavior in Mobile Plan Selection Using Statistical Modeling
NBD · Gamma Distribution · Chi-Square · Q-Q Plots- Fitted Shifted NBD, Truncated NBD, and Gamma models to understand consumer behavior in mobile plan selection.
- Evaluated models using Q-Q plots, chi-square likelihood ratio tests, and p-value assessments.

Deepfake Detection
VideoLaMA · BLIP · LLaVA · Kendall Tau- Evaluated state-of-the-art Video Vision-Language Models for deepfake detection with synthetic data and annotated explanations.
- Employed Kendall Tau’s correlation and reliability analysis to verify inter-annotator agreement on deformation labels.

Traversability Estimation
Semantic Segmentation · Attention-enhanced FCN- Developed a terrain classification model using Semantic Segmentation and an attention-enhanced FCN, achieving a 2% improvement in IoU.
- Enhanced off-road navigation for autonomous vehicles by optimizing path planning and terrain adaptability.

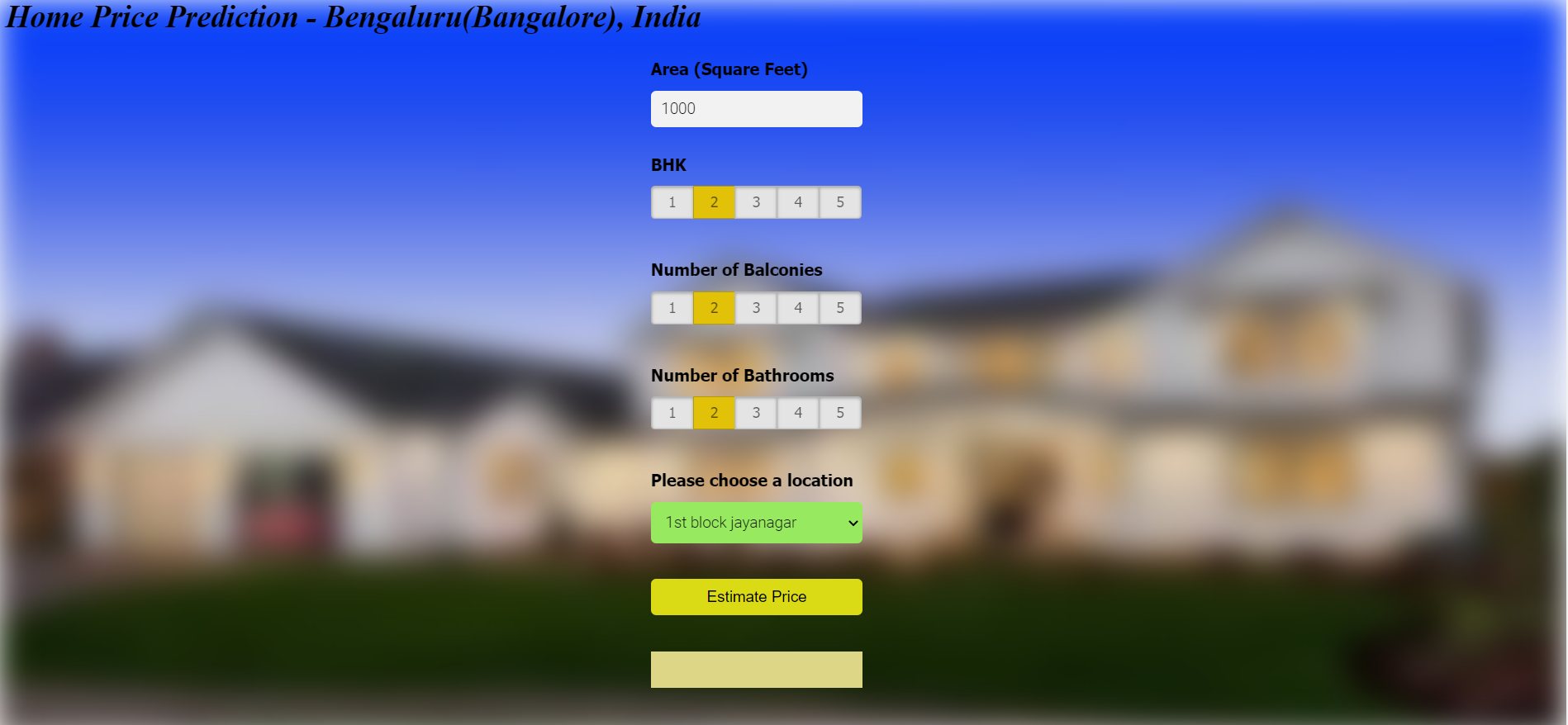
Bangalore House Prediction
sklearn · Linear Regression · GridSearchCV · Flask- Built a ML model with linear regression and GridSearchCV for hyperparameter tuning, evaluated with k-fold cross-validation.
- Deployed via Flask API with an HTML/CSS/JS frontend for dynamic price predictions.
Topic Modelling with Latent Dirichlet Allocation
Gensim · NLTK · SpaCy · LDA- Implemented LDA for topic modeling, classifying text into topics based on underlying word distributions.
- Computed coherence and perplexity scores to optimize topic count; generated interactive visualizations.
